Local AI turns into a real laptop workflow
A Mac app for meeting notes now runs fully on-device through Ollama, keeping transcription, embeddings, and LLM suggestions local.[2] That is a small demo, but it lands because it looks like ordinary software, not a stage-managed reveal.
A few posts away, someone showed a 397-billion-parameter model running on a MacBook by streaming weights from SSD and activating only a few experts per token.[33] One example is practical and easy to picture. The other is a systems stunt. Together, they capture the current moment in local AI: useful desktop workflows and boundary-pushing experiments are arriving at once.[3 refs]Citations[2][30][33]
The shift is not just about models getting smaller or faster. It is about a stack taking shape around them. Runtimes, packaging, orchestration, and shared habits are making local AI easier to try and easier to keep using.[3 refs]Citations[1][2][30] In these posts, the center of attention is moving from “can this run?” to “how do people actually work with it once it does?”[7][12]
From stunt to routine
You can see that change in the questions people ask. One Reddit thread asks for the most-used Claude Code development workflows. Another asks how to set up a Claude Code project.[7][12] Those are not first-contact questions. They show up when a tool has entered regular use.
The OpenGranola example carries the same tone. Transcription, embeddings, and LLM suggestions are familiar software jobs.[2] The notable part is where the data stays.
Consumer hardware is part of the story too. One widely shared X post argued that an open model could run on a base Mac mini and urged anyone with a modern computer to try it.[26] The post is promotional, but the practical point still holds: local AI is no longer framed only as a server-room activity.[26]
Personal projects make that shift easier to picture. One user said they had “vibecoded” a roughly 2250 Elo chess engine that runs locally on a Mac in Rust.[46] Buying decisions reflect the same interest. A student comparing a MacBook Pro with an NVIDIA/CUDA laptop said the choice mattered because they wanted to experiment with local models while doing AI and ML work.[59]
The layer around the model matters
Much of the momentum in these posts comes from workflow design rather than raw model quality. Codex subagents are a clear example. OpenAI Developers said users can “spin up specialized agents,” keep the main context window cleaner, and work on parts of a task in parallel.[1]
That framing matters because it treats AI less like a single assistant and more like a system that benefits from structure. Other posts make the same case in plainer terms. Users trade setup advice, feature lists, cheatsheets, and hook guides for Claude Code.[5 refs]Citations[7][19][20][45][56]
On X, one post pointed readers to a “130+ subagent” collection for development workflows.[40] Another showed how to define a custom subagent.[55] Elsewhere, users shared “buddies,” slash commands, and hidden features they rely on in daily use.[3 refs]Citations[18][44][45]
This is often what software looks like when it starts to settle into practice. The conversation gets less abstract. More attention goes to configuration, decomposition, and repeatable habits.[3 refs]Citations[7][20][40]
Why context keeps breaking the experience
Many posts about coding assistants circle the same problem: long threads become messy and harder to use. One Reddit explanation of Codex subagents says everything runs in a single thread, that the thread fills with noise, and that performance drops as context gets cluttered.[31] A separate visual guide makes the same case.[52]
Subagents are presented as one answer to that problem. In the Reddit explanation, they “fix this by splitting the work.”[31] Another post describes the benefit as compression: a subagent works in its own context and returns only the result, not every intermediate step.[53] OpenAI Developers’ description fits that logic.[1]
That does not establish a grand theory of AI. It does show what users are trying to solve right now. The practical issue is often not generation in the abstract. It is keeping a working session coherent enough to remain useful over time.[4 refs]Citations[1][31][52][53]
Why local inference feels more plausible
Part of the new plausibility comes from software lower in the stack. Ollama said its update runs “the fastest on Apple silicon, powered by MLX,” and described the change in terms of personal assistants and coding agents on macOS.[30] Another X post put it more simply: Ollama can now use MLX as a backend.[32]
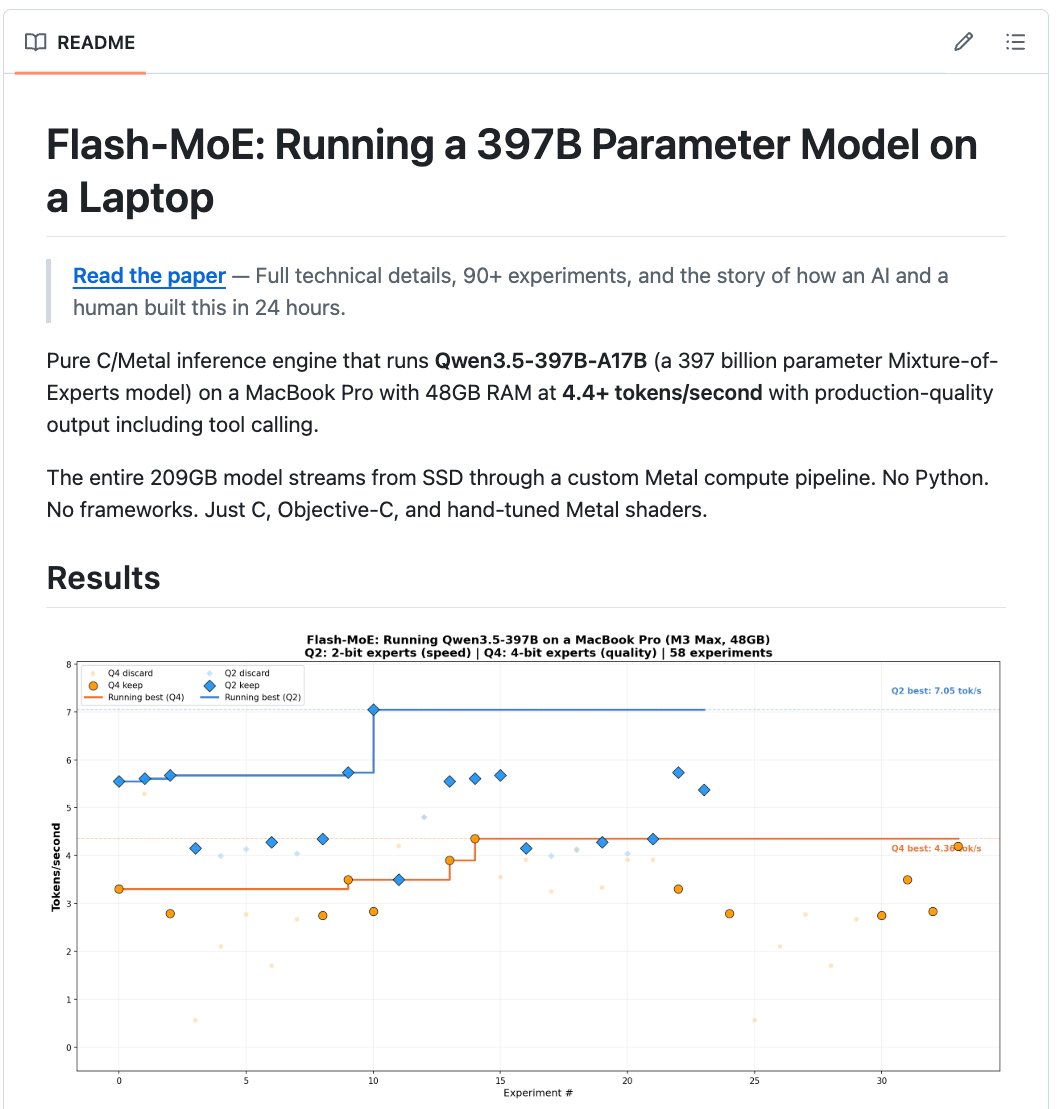
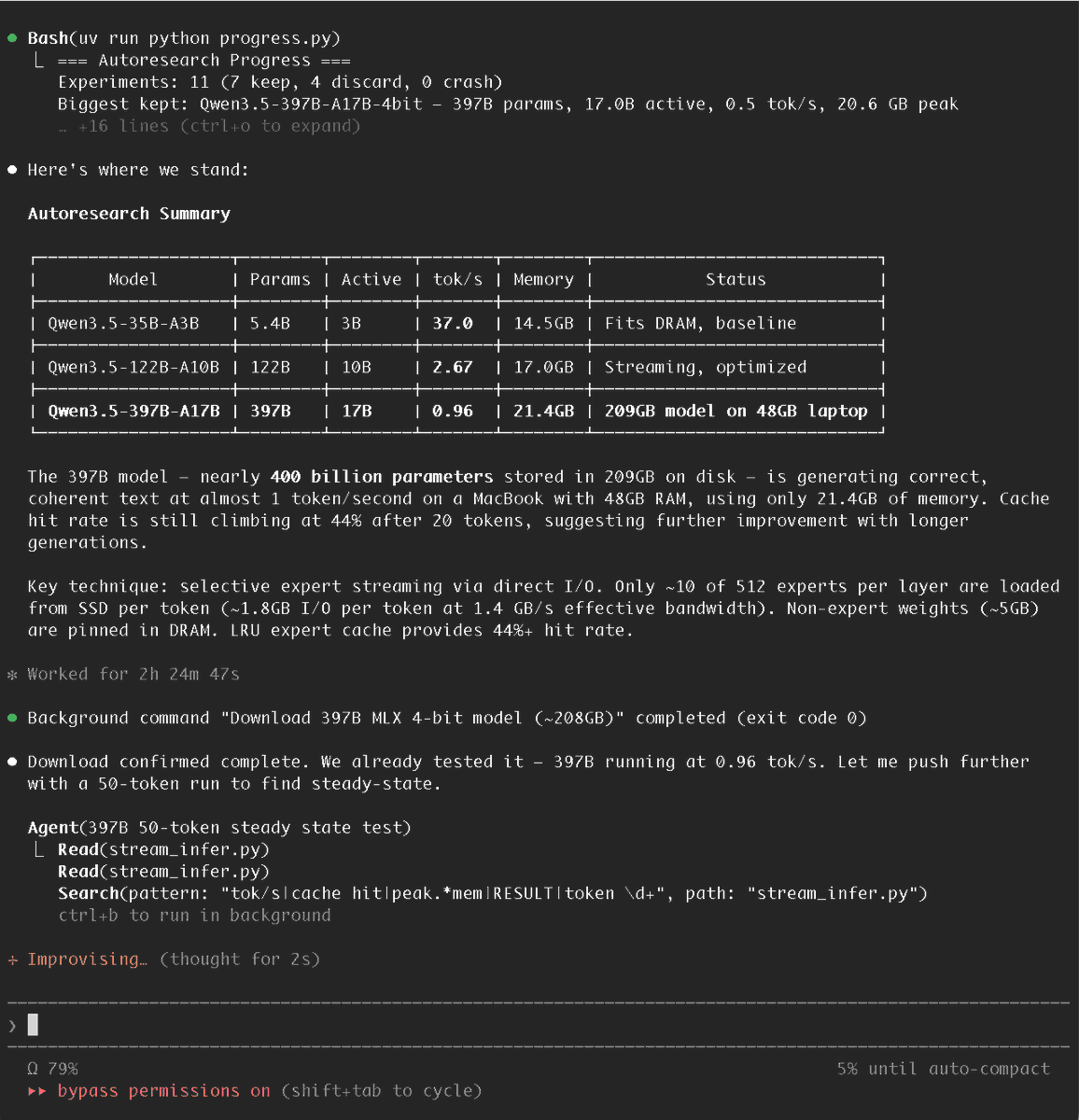
Then there are the edge cases that stretch expectations. The flash-moe demonstration said a pure C and Metal engine could run Qwen3.5-397B on a 48GB MacBook Pro at 4.4 tokens per second by streaming a 209GB model from SSD and activating only four experts per token out of 512.[33] A separate post highlighted the same feat as an “impossible” laptop run.[43]
That is not evidence that giant local models are now routine. It is evidence that systems work — sparse activation, hardware-specific kernels, and storage tricks — is changing what counts as possible on a personal machine.[33][43]
Tooling for local training and experimentation is moving in the same direction. Unsloth Studio is presented as a free open-source UI to train and run LLMs locally, with claims of faster training and lower VRAM use.[36] Other posts say it can run on Mac, Windows, and Linux, support hundreds of models, and turn documents into datasets.[48][49] Those details need outside verification, but the packaging trend is clear: more of this work is being wrapped in software that non-specialists can at least attempt to use.[3 refs]Citations[36][48][49]
BitNet points to a similar idea from another angle. Posts about Microsoft’s framework say it uses ternary weights and can run a 100B-parameter LLM on a single CPU, with lower memory and energy demands.[50][51] The posts are breathless, but they still point to a real systems question: how much can algorithmic design change hardware assumptions?[50][51]
Why the Mac keeps showing up
In posts about local AI for individuals, the Mac appears again and again. OpenGranola’s local setup was shown on a Mac.[2] Ollama’s MLX update is explicitly about Apple silicon.[30][32] The 397B demonstration was framed around a MacBook.[33]
That repetition does not settle the broader hardware debate. It does suggest that Apple laptops have become a visible target for local inference and desktop-native AI workflows.[3 refs]Citations[2][30][33] The student choosing between a MacBook Pro and an NVIDIA/CUDA laptop makes the tradeoff explicit: one path favors local experimentation and on-device use, while the other favors CUDA-dependent training and compatibility with much of the research stack.[59]
So the Mac story needs restraint. These posts support a narrower claim than “the Mac won AI.” They support the idea that Apple hardware has become a credible home for some kinds of local AI use, especially inference and personal tooling.[4 refs]Citations[2][30][32][59]
The draw is not only cost
Cost comes up often in these discussions, but not cleanly. One Reddit post claimed Claude Code could become “50-70% cheaper” if used correctly.[9] Another pushed back and said claims of 90 percent savings were probably a scam.[10] The disagreement matters because it shows what users are measuring now: not just capability, but the cost of living with these tools.[9][10]
Privacy and control matter too. In the OpenGranola post, “nothing hits the network” is the headline feature.[2] A Reddit user asking how safe Claude’s long-term memory features are, security-wise, is asking a different version of the same question: what happens to the data once these systems become part of daily work?[3]
That helps explain the appeal of local and self-hosted setups. One viral post sold local open models as private intelligence on your desk.[26] The flash-moe demo used similar language: offline, private, no API key, no monthly bill.[33] The wording is heavy on marketing, but the preference behind it is easy to recognize. For many users, “local” is partly a performance choice and partly a trust-boundary choice.[4 refs]Citations[2][3][26][33]
A culture of guides and status signals
Maturing software ecosystems produce manuals. This one produces manuals, cheatsheets, feature threads, and power-user guides. Users compile Claude use cases, organize repositories, share cheatsheets, and post hidden-feature lists.[5 refs]Citations[5][6][17][20][45]
Some of that is plainly useful. The tools are changing quickly, and much of the value seems to sit in defaults, hooks, commands, and combinations that are easy to miss.[4 refs]Citations[19][20][45][56] Boris Cherny’s thread on underused Claude Code features spread because it addressed that gap directly.[45]
Some of it is performative too. Posts promise the top GitHub repos to improve your workflow, or a complete guide to becoming a top 1 percent power user, or a way to master Claude in a week.[3 refs]Citations[21][29][35] That mix of instruction and status signaling is common in young software cultures. It suggests a field where practical literacy is growing, but the norms are still unstable.[3 refs]Citations[17][21][35]
The friction is still there
None of this means the tools are settled. Hype remains a problem. The cost-savings fight around Claude Code is one example, with one set of users posting dramatic efficiency claims and another disputing them.[9][10]
Product churn is another. Reddit users track rollbacks and new modes closely, including a thread about Claude being rolled back to version 2.1.87 and another about “NO_FLICKER Mode.”[15][25] Those are ordinary product events, but they matter because people are trying to build habits on top of systems that can change quickly.[15][25]
New capabilities bring their own uncertainty. Posts celebrating “computer use” in Claude Code sit beside posts asking whether this changes everything or whether the feature is finally ready.[3 refs]Citations[54][57][58] The excitement is obvious. So is the unresolved question of how reliable and safe these tools are when they move from suggesting text to acting more directly.[3 refs]Citations[54][57][58]
Beyond chat
The local and open shift is not limited to coding assistants. Posts about Google’s TimesFM describe a time-series model for forecasting sales, prices, traffic, and energy demand, with emphasis on local use and open availability.[37][42] A post about NForge describes an open-source framework for predicting brain responses to text, audio, or video.[16]
Outside language models, Flash-KMeans is presented as an IO-aware implementation of exact k-means with large speed gains over existing GPU tools.[4] A Reddit discussion in operations research asks how widely GPU-based combinatorial optimization might apply.[14] Parameter Golf turns model efficiency into a public contest with a 16MB limit.[38]
These examples are uneven, and some are plainly promotional. Even so, they point in the same direction: open models, better runtimes, and community packaging can move a capability from lab curiosity toward something a person or small team might actually try.[4 refs]Citations[4][16][37][38]
The old AI drama was the reveal. A company stepped onstage and showed what the future could do. The newer drama is quieter. Someone points a Mac app at Ollama and keeps meeting notes offline.[2] Someone else splits a coding task across subagents so the main thread stays usable.[1][31] Someone streams a giant model from SSD just to see how far a laptop can be pushed.[33]
The cloud is not going away, and local tools have not solved reliability, churn, or trust. But the social evidence here does support one clear change: more people are treating AI as something they can assemble into a personal system, not only something they rent as a service.[3 refs]Citations[2][26][40] The interesting question now is not whether every workflow will move onto the laptop. It is how many small decisions about privacy, speed, cost, and control are starting there first.